FluxVLA Engine文档#

欢迎来到 FluxVLA!
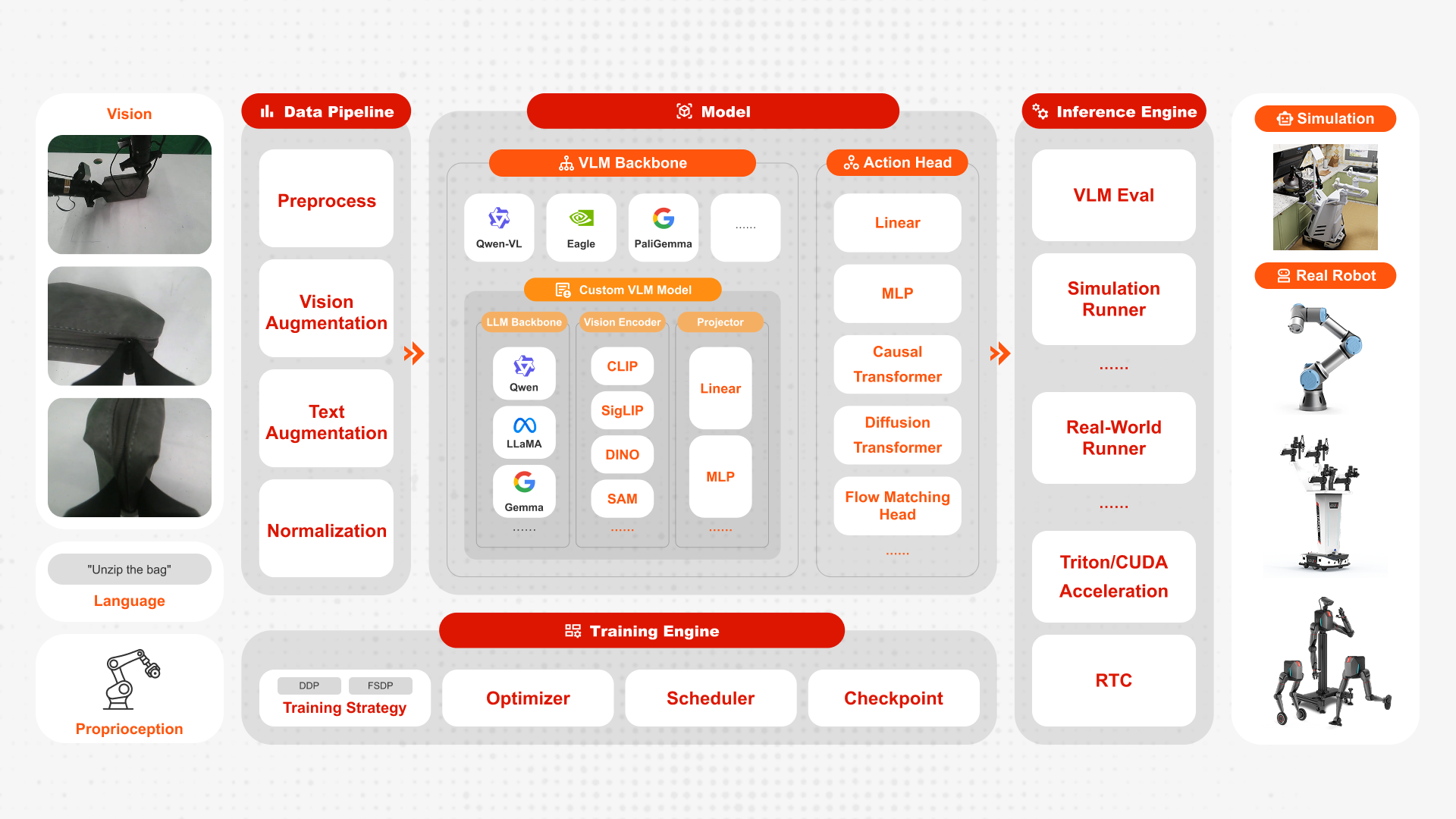
FluxVLA Engine 是面向具身智能应用的全栈端到端工程平台,依托统一配置、标准化接口、模块解耦与可部署性等设计原则,打通从数据到真机部署的完整工程闭环,为产学研提供标准化底座,显著降低 VLA 研发工程门槛。











亮点速览
FluxVLA 的独特之处在于:
统一的模块化 VLA 主干: 所有 Model 均继承 BaseVLA——Vision Encoder、Language Encoder、向 LLM 嵌入空间的 Projection Layer 与 Action Prediction Head——因此可在 OpenVLA、LlavaVLA、GR00T、Pi0 与 Pi0.5 之间切换,而无需重写整套 Training 流程。
骨干网络覆盖
Language Model: LLaMA、Gemma、Qwen 等系列。
视觉: DinoSigLIP(DINO + SigLIP)。
视觉-语言: PaliGemma、QwenVL。
Data Format: 原生支持 Parquet 与 RLDS Pipeline,以及面向异构 Data 的 Multi-dataset Mixed Training。
FluxVLA 在规模上做到周全:
Distributed Training: 面向大规模任务的 FSDP 与 DDP。
实用 Training Stack: LoRA、Mixed Precision(AMP)、Checkpoint Resume 与 Training 结束后的自动 Evaluation。
从 Benchmark 到 Real-robot: 多 GPU Evaluation、LIBERO(含无光线追踪环境,例如 A100)、Real-robot Inference Script,以及 跳过加载完整 Pretrained Weight 的 Inference Mode 以节省显存。
FluxVLA 灵活且易用:
清晰的项目结构: fluxvla/ 涵盖 Model(VLA、Backbone、Head、Projector)、Dataset、Transform、Tokenizer、Engine、Optimizer 与 Collator;configs/ 按 Model Family 组织(openvla、llava、gr00t、pi0、pi05);scripts/ 串联 Training、Evaluation 与 Real-robot Inference。
端到端 Data 与 Training Flow: 从 Parquet 或 RLDS Loading → Transform 与 Batch Assembly → Forward → Action Loss → Backward,配合可插拔 Runner(FSDP/DDP)以及 Standard Optimizer、Log 与 Checkpoint。
成熟工具链: PyTorch 2.6、Hugging Face Transformers 4.53.x、Flash Attention 2.5.x、用于 RLDS 的 TensorFlow,以及 LIBERO——适用于操作、多任务学习、迁移学习与 VLA 研究迭代。
路线图展望: 更多视觉/VLM 骨干与 VLA 方法、VLM 或思维链(CoT)数据训练、Isaac Sim 集成与更完善的日志能力。