FluxVLA代码架构概览#
本页用于快速建立对 FluxVLA code structure 的整体认知,帮助你在阅读、调试与二次开发时更快定位关键模块。
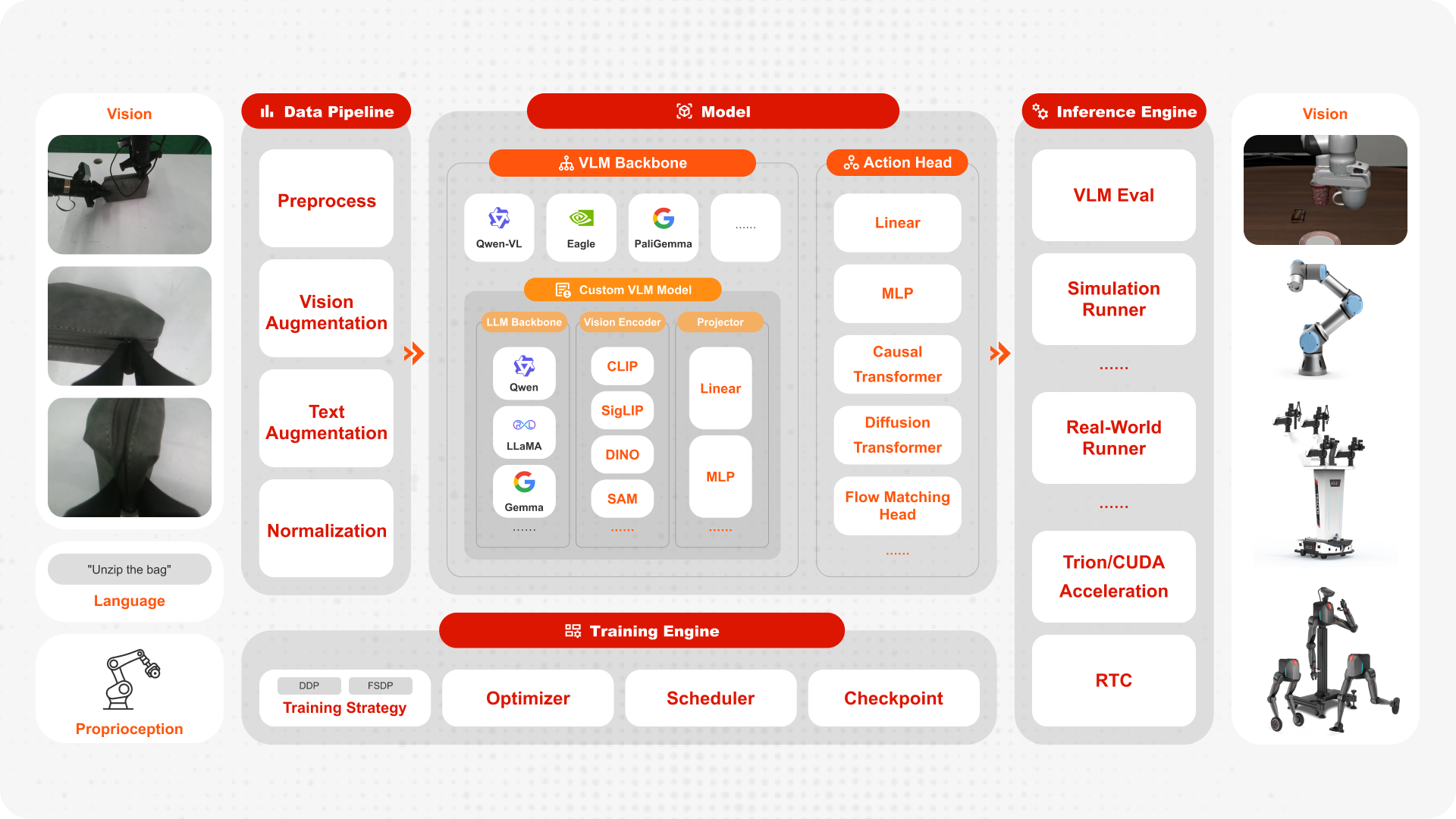
一、代码组织总览#
FluxVLA 的 project structure 清晰,核心目录职责如下:
fluxvla/(核心实现)覆盖 Model 相关模块:
VLA、Backbone、Head、Projector。同时包含
datasets、transformers、tokenizer、engine、optimizer等 training/inference 核心组件。
configs/(配置组织)按 model families 组织:
openvla、llava、groot、pi0、pi05。用于统一描述 Model、Data、Training、Evaluation 与 Inference 参数。
scripts/(流程入口)串联 training、evaluation 与 real-robot inference 流程。
常用入口包括
scripts/train.sh、scripts/eval.sh、scripts/inference_real_robot.py。
二、端到端 Data 与 Training Flow#
一个常见的 end-to-end execution flow 如下:
从 Parquet 或 RLDS 加载 Data
经过
transformers/Data Transform 与 Batch 组装执行 Model
forward计算 Action Loss
执行
backward配合 FSDP/DDP、Standard Optimizer、Log 与 Checkpoint 完成 Training Loop
该流程覆盖从 Data Loading 到 Distributed Training Convergence 的关键路径,也直接对应 configs/ 与 scripts/ 的参数组织方式。
三、典型 Execution Chain#
一个常见的 execution chain 如下:
读取 Config → 构建 Dataset 与 Data Loader → 构建 Model 与 Modules → 启动 Training/Evaluation Engine → 输出 Log 与 Checkpoint → 执行 Inference。
你可以结合以下教程逐层深入:
:doc:
config/index:doc:
private_model:doc:
private_module:doc:
private_engine:doc:
private_dataset_config:doc:
inference/index
四、阅读建议#
先看 config:先明确 experiment goals 与 key hyperparameters。
再看 module interfaces:关注 input/output tensors、loss terms 与 key intermediate variables。
最后看 execution loops:重点理解 training step、evaluation step 和 checkpoint-saving logic。
这样可以用最短路径建立“config → code → results”的因果关系。