推理加速#
FluxVLA 为 GR00T 与 PI0.5 提供面向推理优化的模型变体,通过 Triton 融合算子、CUDA Graph(CUDA 图)捕获 与 算法层优化 的组合,在 A100 硬件上可获得显著加速(GR00T 约 5×,PI0.5 约 15×,均为相对基线的量级,具体依赖配置与批次)。
概述#
典型视觉–语言–动作(VLA)推理管线的高延迟常来自以下因素:
算子启动开销大:eager 执行与频繁的 host 侧调度导致内核启动成本累积。
算子链未融合:多段算子反复读写全局内存中的中间张量。
执行路径未捕获:无法形成可完全静态重放的 GPU 工作负载。
FluxVLA 主要从三类技术缓解上述瓶颈:
技术 |
说明 |
适用模型 |
|---|---|---|
Triton 融合内核(Triton Fused Kernels) |
将多类算子(如 Norm + 矩阵乘 + 激活、QKV 投影 + RoPE 等)融合为单次 GPU 内核调用 |
GR00T、PI0.5 |
CUDA Graph 捕获 |
将前向路径预录为 CUDA Graph,重放时显著降低逐步 CPU 启动开销 |
GR00T、PI0.5 |
CUDA 自定义算子 |
手写 CUDA C++ 内核,针对 cublasLt 融合 GEMM+Bias 及旋转位置编码等计算热点 |
GR00T、PI0.5 |
加速技术#
1. Triton 融合内核#
实现位于 fluxvla/ops/triton/。通过将多步运算合并为单一 GPU 内核,减少中间结果的内存读写:
Norm 融合(
norm_triton_ops.py):将残差相加 + LayerNorm、自适应 LayerNorm(scale/shift)、RMSNorm 等融合为单内核(如add_residual_layer_norm_kernel、ada_layer_norm_kernel、adarms_norm_kernel)。注意力投影 + RoPE(
attention_triton_ops.py):单内核matmul_rope_qkv完成 QKV 线性投影、拆分为 Q/K/V,并施加旋转位置编码(RoPE),替代原先 3 次以上的独立调用。门控 MLP 融合(
matmul_triton_ops.py):qwen3_mlp_gate_up_silu_kernel将 gate 投影、up 投影、SiLU 激活与逐元素乘融合,有利于 LLM 主干吞吐。矩阵乘 + 偏置 + 激活(
matmul_triton_ops.py):matmul_small_bias_gelu/matmul_small_bias_silu在分块矩阵乘之后直接融合偏置与激活。位置编码融合(
position_embedding.py):原地融合位置嵌入查表与相加,避免额外中间张量分配。
2. CUDA Graph 捕获#
CUDA Graph 将 GPU 内核序列预先录制,重放时几乎无需 CPU 参与调度,从而显著降低启动开销。
GR00T(FlowMatchingInferenceHead):
将模型权重与中间缓冲展平为裸字典(
self.weights、self.buffers),绕开nn.Module带来的额外开销。以纯函数式风格构建前向,再用
torch.cuda.CUDAGraph()捕获。图经预热后录制一次,后续推理均通过重放该图完成。
PI0.5(PI05FlowMatchingInference):
将 整条管线(视觉编码器、Transformer 编码器及解码器循环)捕获为 单一统一 CUDA Graph,减少多图切换开销。
以 Triton 融合原子操作(如
rms_matmul_qkv_rope、adarms_norm_style_proj等)手工展开,替代各nn.Module的 forward。按最大序列长度预分配缓冲(
self._triton_bufs),满足 CUDA Graph 对静态内存布局的要求。
3. CUDA 自定义算子#
实现位于 fluxvla/ops/cuda/,为计算密集、且需要比 Triton 更底层控制的场景提供手写内核:
cublasLt 融合 GEMM + Bias(+ 残差)(
matmul_bias/):通过 NVIDIA cublasLt API 与CUBLASLT_EPILOGUE_BIAS,将矩阵乘、偏置及可选残差相加合并为单次内核启动,减少中间张量与额外访存:matmul_bias: D(M,N) = inp(M,K) @ weight(K,N) + bias(N) matmul_bias_res: D(M,N) = inp(M,K) @ weight(K,N) + bias(N) + res(M,N)
支持预分配输出张量,以便与 CUDA Graph 协同。
Gemma 旋转位置编码(
gemma_rotary_embedding/):单遍内核由position_ids与inv_freq直接计算cos/sin嵌入,并利用共享内存缓存位置索引以改善合并访问;相对 PyTorch 多步实现(外积 → cos/sin → 拼接等)更为紧凑。旋转位置编码施加(
rotary_pos_embedding/):将rotate_half、逐元素乘与加融合为单内核,在设备端直接计算q_embed = q * cos + rotate_half(q) * sin;支持 bf16 与 fp32,每个 CUDA block 处理一个(batch, head, position)元组以提升并行度。
配置#
推理加速通过在配置中声明 inference_model(GR00T)或选用推理专用模型类(PI0.5)启用。以下为示例片段。
GR00T 示例#
参见 configs/gr00t/gr00t_eagle_3b_libero_10_full_finetune.py:
inference_model = dict(
type='LlavaVLA',
pretrained_name_or_path='./checkpoints/GR00T-N1.5-3B',
vlm_backbone=dict(
type='EagleInferenceBackbone', # 面向推理优化的骨干
vlm_path='fluxvla/models/third_party_models/eagle2_hg_model'),
vla_head=dict(
type='FlowMatchingInferenceHead', # CUDA Graph + Triton 内核
diffusion_model_cfg=dict(
...
)))
与训练用 model 的主要差异:
EagleBackbone→EagleInferenceBackbone(FlashAttention 2、优化后的类型转换等)FlowMatchingHead→FlowMatchingInferenceHead(CUDA Graph、Triton 内核、函数式 API)
PI0.5 示例#
参见 configs/pi05/pi05_paligemma_libero_10_full_finetune.py:
PI0.5 使用统一推理类 PI05FlowMatchingInference,以 Triton 融合算子与 单张 CUDA Graph 替换整条管线;在评测流程中会自动选用该推理模型。
基准测试#
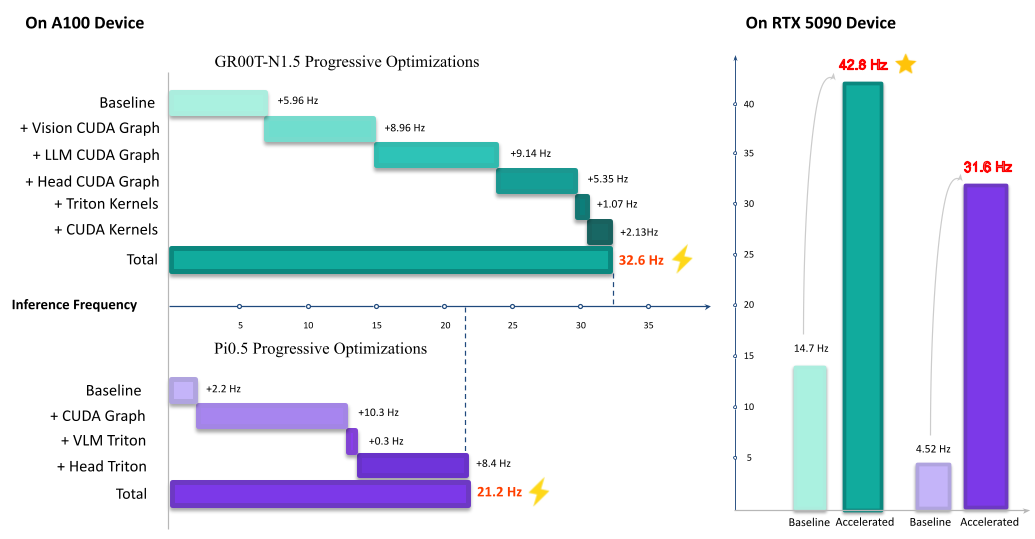
A100 设备(推理频率,Hz)#
模型 |
基线 (Hz) |
加速后 (Hz) |
加速比 |
|---|---|---|---|
GR00T |
5.96 |
32.6 |
5.47× |
PI0.5 |
2.2 |
21.2 |
9.64× |
RTX 5090 设备(推理频率,Hz)#
模型 |
基线 (Hz) |
加速后 (Hz) |
加速比 |
|---|---|---|---|
GR00T |
14.7 |
42.6 |
2.90× |
PI0.5 |
4.52 |
31.6 |
6.99× |