Inference Acceleration#
FluxVLA provides inference-optimized model variants for GR00T and PI0.5, achieving significant speedups on A100 hardware (GR00T ~5x, PI0.5 ~15x) through a combination of custom Triton kernels, CUDA Graphs, and algorithmic optimizations.
Overview#
Standard VLA inference pipelines often show high latency due to:
High kernel launch overhead from eager-mode execution and frequent host-side dispatch.
Unfused operator chains that repeatedly read and write intermediate tensors in global memory.
Non-captured execution paths that prevent fully static, replayable GPU workloads.
FluxVLA addresses these bottlenecks with three core techniques:
Technique |
Description |
Applicable Models |
|---|---|---|
Triton Fused Kernels |
Custom Triton kernels that fuse multiple ops (norm + matmul + activation, QKV projection + RoPE, etc.) into single GPU kernels |
GR00T, PI0.5 |
CUDA Graph Capture |
Pre-record the forward pass into CUDA Graphs to remove per-step CPU launch overhead |
GR00T, PI0.5 |
CUDA Custom Operators |
Hand-written CUDA C++ kernels for cublasLt fused GEMM+Bias and Rotary Embedding computation |
GR00T, PI0.5 |
Acceleration Techniques#
1. Triton Fused Kernels#
Located in fluxvla/ops/triton/, these custom kernels eliminate intermediate memory reads/writes by fusing multiple operations into single GPU kernels:
Norm Fusion (
norm_triton_ops.py): Fuses residual addition + LayerNorm, Adaptive LayerNorm (scale/shift), and RMSNorm into single kernels (add_residual_layer_norm_kernel,ada_layer_norm_kernel,adarms_norm_kernel).Attention Projection + RoPE (
attention_triton_ops.py): A single kernel (matmul_rope_qkv) performs QKV linear projection, splits into Q/K/V, and applies Rotary Positional Embeddings — replacing 3+ separate operations.Gated MLP Fusion (
matmul_triton_ops.py):qwen3_mlp_gate_up_silu_kernelfuses gate projection, up projection, SiLU activation, and element-wise multiply into one kernel, critical for LLM backbone throughput.Matmul + Bias + Activation (
matmul_triton_ops.py):matmul_small_bias_gelu/matmul_small_bias_siluappend bias addition and activation directly after block-wise matrix multiplication.Position Embedding Fusion (
position_embedding.py): In-place fused position embedding lookup and addition, avoiding intermediate tensor allocation.
2. CUDA Graph Capture#
CUDA Graphs pre-record GPU kernel sequences and replay them without CPU involvement, drastically reducing launch overhead.
GR00T (FlowMatchingInferenceHead):
Flattens all model weights and intermediate buffers into raw dictionaries (
self.weights,self.buffers), bypassingnn.Moduleoverhead.Uses purely functional operations to build the forward pass, then captures it with
torch.cuda.CUDAGraph().The graph is warmed up, recorded once, and replayed for all subsequent inference calls.
PI0.5 (PI05FlowMatchingInference):
Goes further by capturing the entire pipeline — vision encoder, transformer encoder, and transformer decoder loop — into a single unified CUDA Graph, eliminating inter-graph overhead.
All
nn.Moduleforward passes are replaced with manual unrolling using Triton-fused atomic ops (rms_matmul_qkv_rope,adarms_norm_style_proj, etc.).Pre-allocates all buffers (
self._triton_bufs) with fixed maximum sequence lengths to enable static memory allocation required by CUDA Graphs.
3. CUDA Custom Operators#
Located in fluxvla/ops/cuda/, these are hand-written CUDA C++ kernels targeting compute-bound hotspots that benefit from low-level hardware control beyond what Triton provides:
cublasLt Fused GEMM + Bias (+ Residual) (
matmul_bias/): Uses NVIDIA cublasLt API withCUBLASLT_EPILOGUE_BIASto fuse matrix multiplication, bias addition, and optional residual addition into a single kernel launch. Avoids intermediate tensor allocation and extra memory round-trips:matmul_bias: D(M,N) = inp(M,K) @ weight(K,N) + bias(N) matmul_bias_res: D(M,N) = inp(M,K) @ weight(K,N) + bias(N) + res(M,N)
Supports pre-allocated output tensors for CUDA Graph compatibility.
Gemma Rotary Embedding (
gemma_rotary_embedding/): Custom CUDA kernel that directly computescosandsinembeddings fromposition_idsandinv_freqin a single pass, using shared memory to cache position IDs for coalesced access. Replaces the multi-step PyTorch implementation (outer product → cos/sin → concat) with one fused kernel.Rotary Position Embedding Apply (
rotary_pos_embedding/): Fuses therotate_half+ element-wise multiply + addition into a single kernel, directly computingq_embed = q * cos + rotate_half(q) * sinon-device. Supports both bf16 and fp32, with each CUDA block handling one(batch, head, position)tuple for maximum parallelism.
Configuration#
Inference acceleration is enabled by defining an inference_model (for GR00T) or using the inference-specific model class (for PI0.5) in your config. Below are example configurations.
GR00T Example#
See configs/gr00t/gr00t_eagle_3b_libero_10_full_finetune.py:
inference_model = dict(
type='LlavaVLA',
pretrained_name_or_path='./checkpoints/GR00T-N1.5-3B',
vlm_backbone=dict(
type='EagleInferenceBackbone', # Inference-optimized backbone
vlm_path='fluxvla/models/third_party_models/eagle2_hg_model'),
vla_head=dict(
type='FlowMatchingInferenceHead', # CUDA Graph + Triton kernels
diffusion_model_cfg=dict(
...
)))
Key differences from the training model:
EagleBackbone→EagleInferenceBackbone(FlashAttention 2, optimized casting)FlowMatchingHead→FlowMatchingInferenceHead(CUDA Graph, Triton kernels, functional API)
PI0.5 Example#
See configs/pi05/pi05_paligemma_libero_10_full_finetune.py:
PI0.5 uses a unified inference model class PI05FlowMatchingInference that replaces the entire pipeline with Triton-fused operations and a single CUDA Graph. The inference model is automatically selected during evaluation.
Benchmarks#
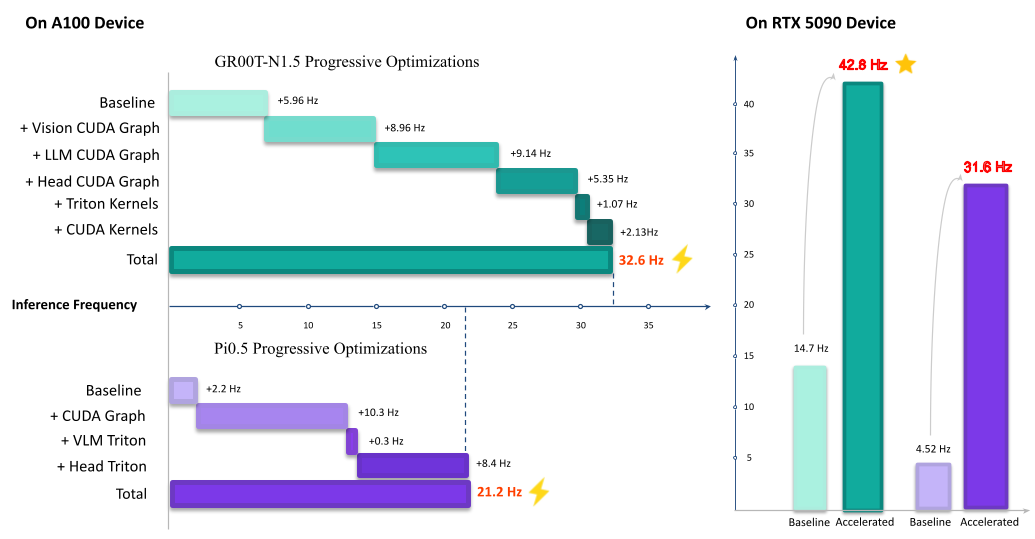
On A100 Device (Inference Frequency)#
Model |
Baseline (Hz) |
Accelerated (Hz) |
Speedup |
|---|---|---|---|
GR00T |
5.96 |
32.6 |
5.47x |
PI0.5 |
2.2 |
21.2 |
9.64x |
On RTX 5090 Device (Inference Frequency)#
Model |
Baseline (Hz) |
Accelerated (Hz) |
Speedup |
|---|---|---|---|
GR00T |
14.7 |
42.6 |
2.90x |
PI0.5 |
4.52 |
31.6 |
6.99x |