FluxVLA Engine Documentation#

Welcome to FluxVLA!
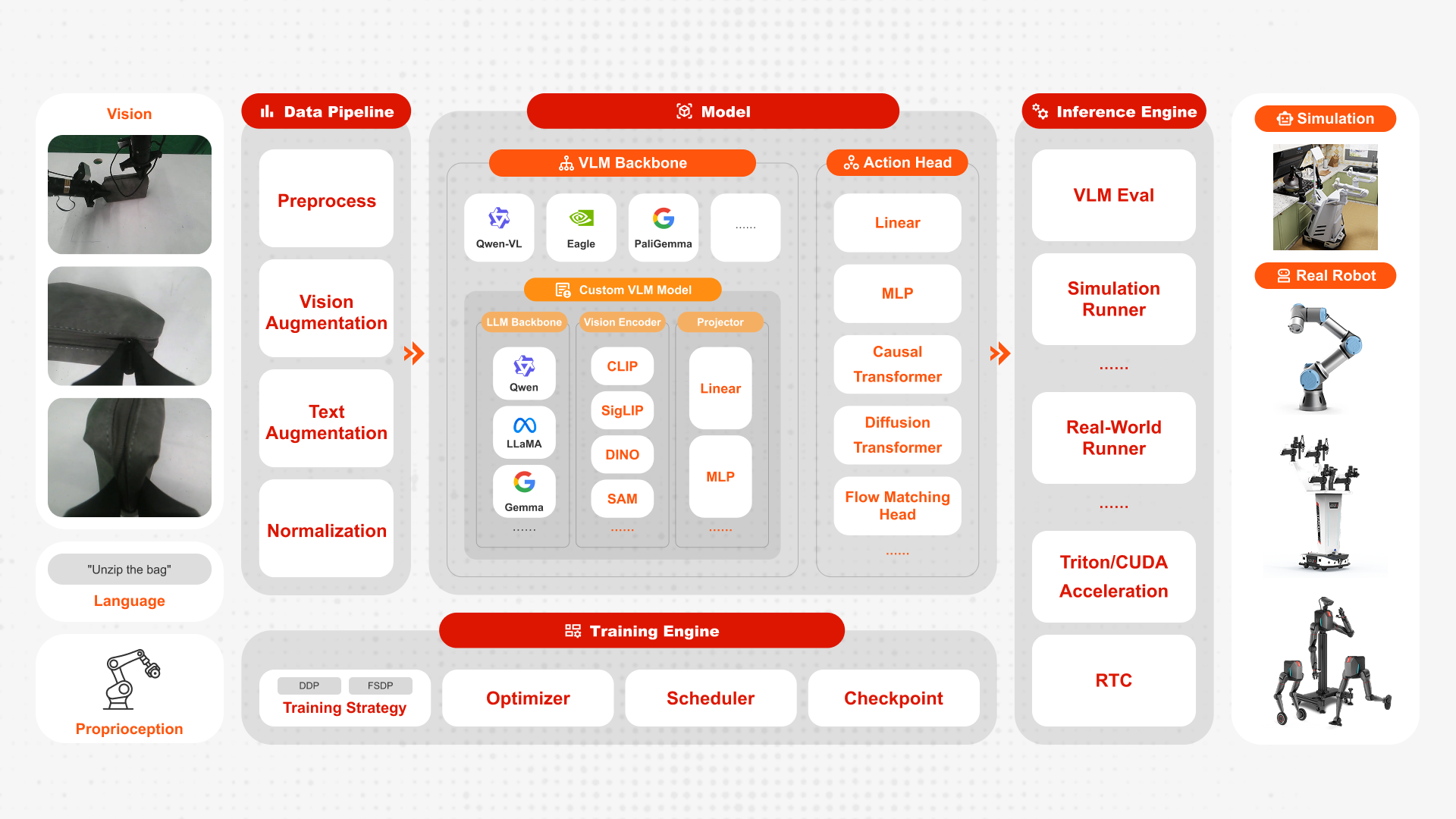
FluxVLA Engine is a full-stack, end-to-end engineering platform for deploying embodied intelligence applications. Built on the core design principles of unified configuration, standardized interfaces, module decoupling, and deployability, it creates a complete engineering loop from data to real-device deployment. With the goal of providing a standardized industry–academia–research foundation, it significantly lowers the engineering barrier for VLA research and development.











Highlights
FluxVLA is unique with:
One modular VLA spine: all models inherit from BaseVLA—vision encoder, language encoder, projection into the LLM space, and an action head—so you can swap OpenVLA, LlavaVLA, GR00T, Pi0, and Pi0.5 without rewriting the training story.
Backbone breadth
LLMs: LLaMA, Gemma, and Qwen families.
Vision: DinoSigLIP (DINO + SigLIP).
VLMs: PaliGemma and QwenVL.
Dataset breadth: first-class Parquet and RLDS pipelines plus multi-dataset mixed training for heterogeneous data.
FluxVLA is complete at scale with:
Distributed training: FSDP and DDP for large-scale runs.
Practical training stack: LoRA, AMP, checkpoint resumption, and automatic post-training evaluation.
From benchmarks to real robots: multi-GPU evaluation, LIBERO (including setups without ray tracing, e.g. A100), real-robot inference scripts, and an inference mode that skips loading full pretrained weights to save memory.
FluxVLA is flexible and easy to use with:
Clear project layout: fluxvla/ holds models (VLAs, backbones, heads, projectors), datasets, transforms, tokenizers, engines, optimizers, and collators; configs/ is organized by family (openvla, llava, gr00t, pi0, pi05); scripts/ wires train, eval, and real-robot inference.
End-to-end data and training flow: load Parquet or RLDS → transform and collate → forward → action loss → backprop, with pluggable runners (FSDP/DDP) and standard optimizers and logging/checkpointing.
Proven tooling: PyTorch 2.6, Hugging Face Transformers 4.53.x, Flash Attention 2.5.x, TensorFlow for RLDS, and LIBERO—suited to manipulation, multi-task learning, transfer learning, and VLA research iteration.
Forward-looking roadmap: more vision/VLM backbones and VLA methods, VLM or chain-of-thought data training, Isaac Sim integration, and richer logging.