FluxVLA Code Architecture Overview#
This page provides a quick overview of the FluxVLA code structure, helping you locate key modules faster when reading, debugging, or extending the framework.
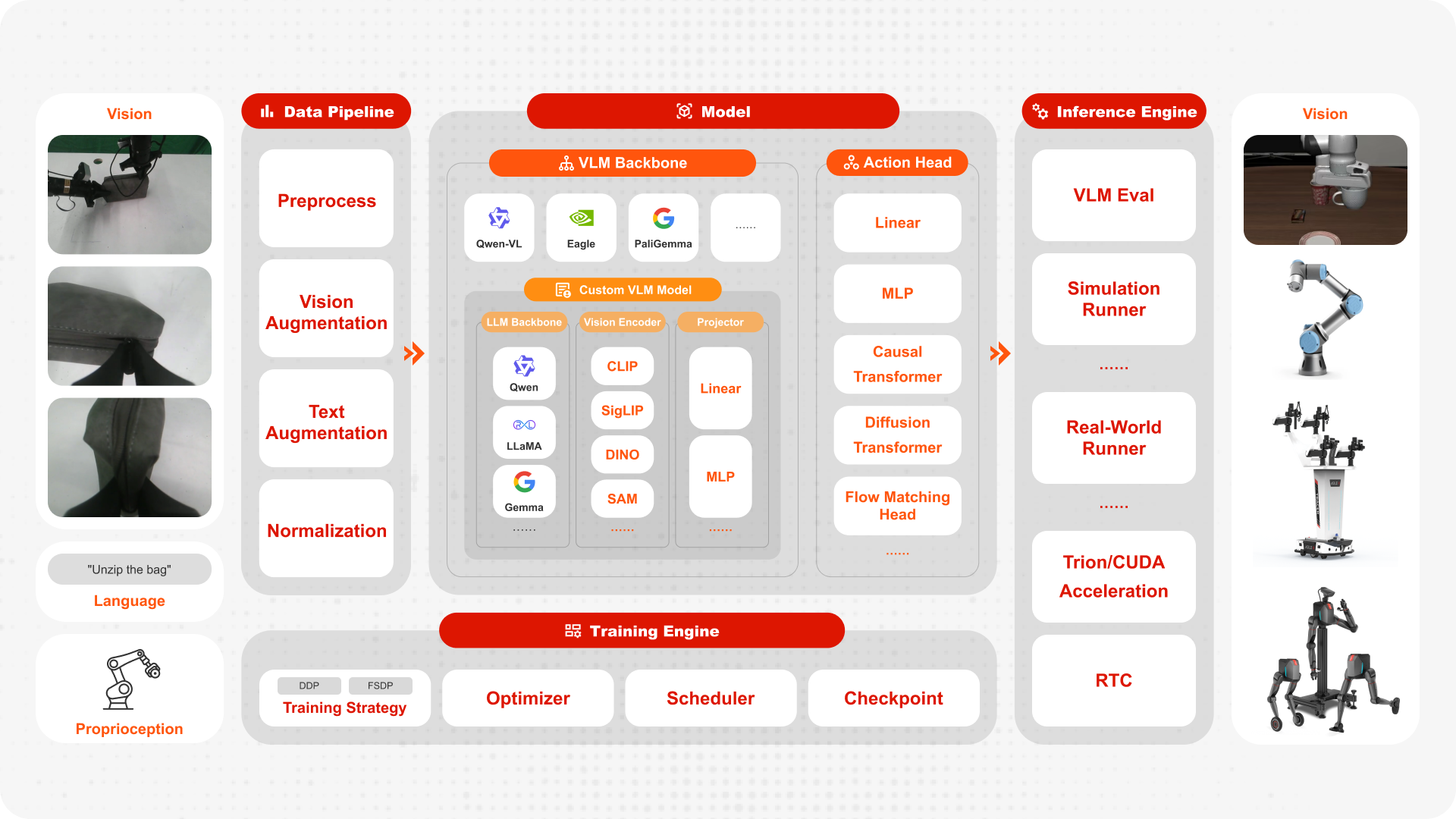
1. Code Organization Overview#
FluxVLA has a clear project structure. The core directories are:
fluxvla/(Core Implementation)Covers model-related modules:
VLA,Backbone,Head, andProjector.Also includes core training/inference components such as
datasets,transformers,tokenizer,engine, andoptimizer.
configs/(Configuration Organization)Organized by model families:
openvla,llava,groot,pi0, andpi05.Unifies model, data, training, evaluation, and inference parameters.
scripts/(Workflow Entrypoints)Connects training, evaluation, and real-robot inference workflows.
Common entrypoints include
scripts/train.sh,scripts/eval.sh, andscripts/inference_real_robot.py.
2. End-to-End Data and Training Flow#
A typical end-to-end execution flow is:
Load data from Parquet or RLDS
Apply
transformers/data transforms and batch assemblyRun model
forwardCompute action loss
Run
backwardComplete the training loop with FSDP/DDP, standard optimizers, logs, and checkpoints
This flow covers the key path from data loading to distributed training convergence, and directly matches how parameters are organized in configs/ and scripts/.
3. Typical Call Chain#
A common execution flow is as follows:
Load config → Build dataset and data loader → Build model and modules → Start training/evaluation engine → Output logs and checkpoints → Run inference.
You can explore each layer in depth through the following tutorials:
:doc:
config/index:doc:
private_model:doc:
private_module:doc:
private_engine:doc:
private_dataset_config:doc:
inference/index
4. Recommended Reading Order#
Start with configuration: Understand experiment goals and key hyperparameters.
Then inspect module interfaces: Focus on input/output tensors, loss terms, and key intermediate variables.
Finally review execution loops: Focus on training steps, evaluation steps, and checkpoint-saving logic.
This gives you the shortest path to understanding the chain from “config → code → results.”